Gráficos de embudo para controlar la varianza en muestras pequeñas
Publiqué hace un tiempo una entrada en esta bitácora sobre el problema que representa la desigualdad de los tamaños muestrales a la hora de comprender cierto tipo de datos, como por ejemplo, los que trata de representar el gráfico
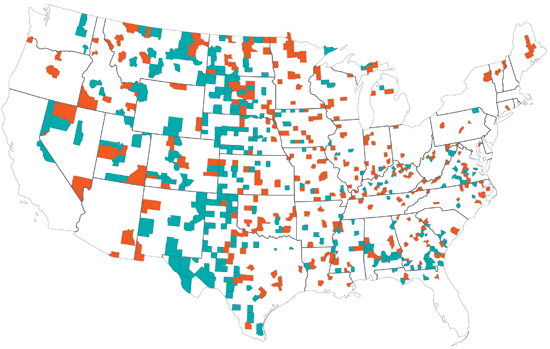
que muestra la incidencia del cáncer de riñón en distintas zonas de en EE.UU. Como indiqué entonces, los valores extremos se encuentran en zonas menos pobladas: cuanto menor es la población, más probables son las proporciones inhabituales.
