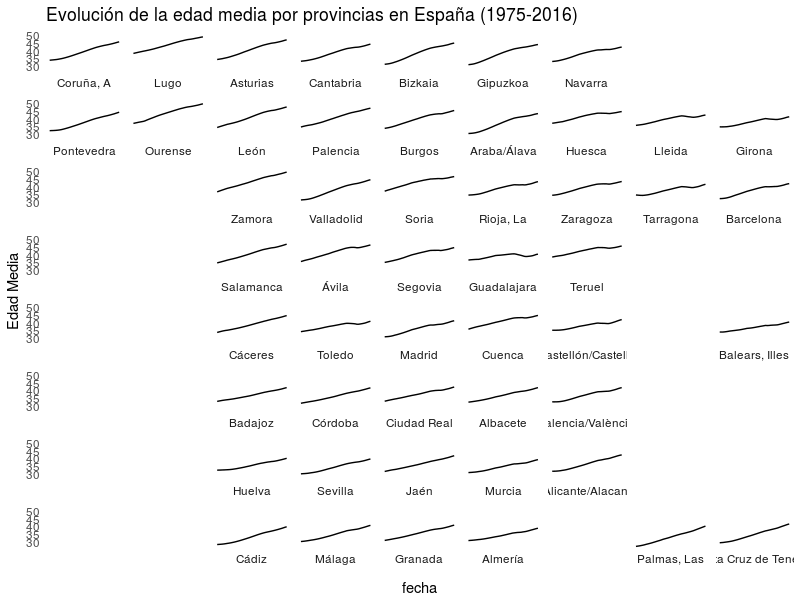
El código, con mínimas modificaciones mías (para automatizar la descarga de los datos) es
library(pxR)
library(dplyr)
library(tidyr)
library(ggplot2)
#---- Carga y transformacion de datos
download.file("http://www.datanalytics.com/uploads/3199.px", "3199.px")
pob <- read.px("3199.px", encoding = "latin1")
pob <- as.data.frame(pob)
pob$Sexo <- NULL
pob$Periodo <- as.numeric(as.character(pob$Periodo))
pob <- separate(pob, Provincias, into = c("id_provincia", "provincia"), sep = 3)
pob$fecha <- as.Date(paste0(pob$Periodo, "-12-31"))
pob <- subset(pob,as.numeric(id_provincia)<=50)
#---- Plot
bl <- sapply(1:22, function(n) paste(rep(" ",n),collapse=""))
pob$provincia.reorder <- factor(
pob$provincia,
levels = c("Coruña, A","Lugo","Asturias","Cantabria","Bizkaia","Gipuzkoa","Navarra",bl[1:2],
"Pontevedra","Ourense","León","Palencia","Burgos","Araba/Álava" ,"Huesca","Lleida","Girona",
bl[3:4],"Zamora","Valladolid","Soria","Rioja, La","Zaragoza","Tarragona","Barcelona",
bl[5:6],"Salamanca","Ávila","Segovia","Guadalajara","Teruel",bl[7:8],
bl[9:10],"Cáceres","Toledo","Madrid","Cuenca","Castellón/Castelló",bl[11],"Balears, Illes",
bl[12:13],"Badajoz","Córdoba","Ciudad Real","Albacete", "Valencia/València",bl[14:15],
bl[16:17],"Huelva","Sevilla","Jaén","Murcia","Alicante/Alacant",bl[18:19],
bl[20:21],"Cádiz","Málaga","Granada","Almería",bl[22],"Palmas, Las","Santa Cruz de Tenerife"))
ggplot(pob, aes(x = fecha, y = value)) +
geom_line() + facet_wrap(~ provincia.reorder,
ncol=9,drop = F, strip.position="bottom") +
labs(title = "Evolución de la edad media por provincias en España (1975-2016)", y="Edad Media") +
theme_classic() +
theme(axis.text.x = element_blank(),
strip.background=element_blank(),
axis.line=element_blank(),
axis.ticks=element_blank())
Se aceptan modificaciones y mejoras, por supuesto. Y si alguien quiere dedicarle el tiempo necesario para crear un paquete en R que lo generalice, creo que será bienvenido por la comunidad.