Cómo apostar si tienes que
Hace unos días recibí esto,
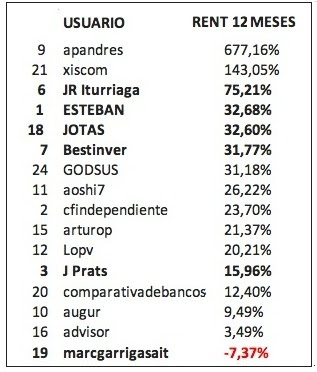
que es la rentabilidad de carteras de inversión (sospecho que no necesariamente reales) de usuarios de cierto portal que compiten por ver quién tiene más ojo en bolsa.
¿No os llama la atención esa rentabilidad >600%? ¿Cómo se puede alcanzar? ¿Es ese señor —a quien no conozco— un hacha de las inversiones?
Dos ideas me vienen a la cabeza. Una es esta que, pienso, no aplica. Y no lo hace porque, en particular, y como ya escribí, la apuesta de Kelly maximiza la mediana de las ganancias, pero ignora su varianza. Que, por lo que veremos luego, es el quid de la cuestión.