¿Qué puede colgar de un árbol?
Predicciones puntuales:

O (sub)modelos:
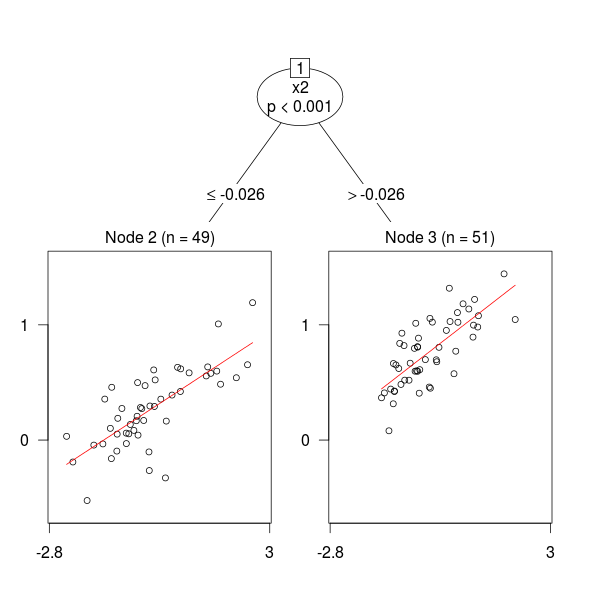
Y parece que ahora también distribuciones:

Notas:
- Obviamente, la clasificación anterior no es mutuamente excluyente.
- La tercera gráfica está extraída de Transformation Forests, un artículo donde se describe el paquete
trtfde R. - Los autores dicen que [r]egression models for supervised learning problems with a continuous target are commonly understood as models for the conditional mean of the target given predictors. ¿Vosotros lo hacéis así? Yo no, pero ¡hay tanta gente rara en el mundo!
- Y añaden que [a] more general understanding of regression models as models for conditional distributions allows much broader inference from such models. Que era lo que creía que todos hacíamos. Menos, tal vez, algún rarito.
