Bajo el capó del particionamiento recursivo basado en modelos
Una de las mayores contrariedades de estar sentado cerca de alguien que es más matemático que un servidor (de Vds., no de silicio) es que oye siempre preguntar por qué. Una letanía de preguntas me condujo a leer papelotes que ahora resumo.
Primero, unos datos:
set.seed(1234)
n <- 100
x1 <- rnorm(n)
x2 <- rnorm(n)
x3 <- rnorm(n)
y <- 0.3 + 0.2 * x1 + 0.5 * (x2 > 0) + 0.2 * rnorm(n)Luego, un modelo:
modelo <- lm(y ~ x1)
summary(modelo)
# Call:
# lm(formula = y ~ x1)
#
# Residuals:
# Min 1Q Median 3Q Max
# -0.9403 -0.2621 0.0420 0.2299 0.6877
#
# Coefficients:
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 0.55632 0.03364 16.538 < 2e-16 ***
# x1 0.21876 0.03325 6.579 2.34e-09 ***
# ---
# Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#
# Residual standard error: 0.3323 on 98 degrees of freedom
# Multiple R-squared: 0.3063, Adjusted R-squared: 0.2992
# F-statistic: 43.28 on 1 and 98 DF, p-value: 2.341e-09Pocos que no entiendan cómo se han generado los datos advertirían lo malo de su especificación: hemos omitido una variable explicativa cuyo efecto ha ido a incrementar el error de manera que los tests habituales de bondad de ajuste no advierten.
Sin embargo,
par(mfrow=c(2,2))
plot(predict(modelo), resid(modelo),
ylab = "residuals", xlab = "predicted values",
main = "resíduos vs predicciones")
plot(x1, resid(modelo), ylab = "residuals", xlab = "x1",
main = "resíduos vs variable x1")
plot(x2, resid(modelo), ylab = "residuals", xlab = "x2",
main = "resíduos vs variable x2")
plot(x3, resid(modelo), ylab = "residuals", xlab = "x3",
main = "resíduos vs variable x3")
par(mfrow=c(1,1))genera
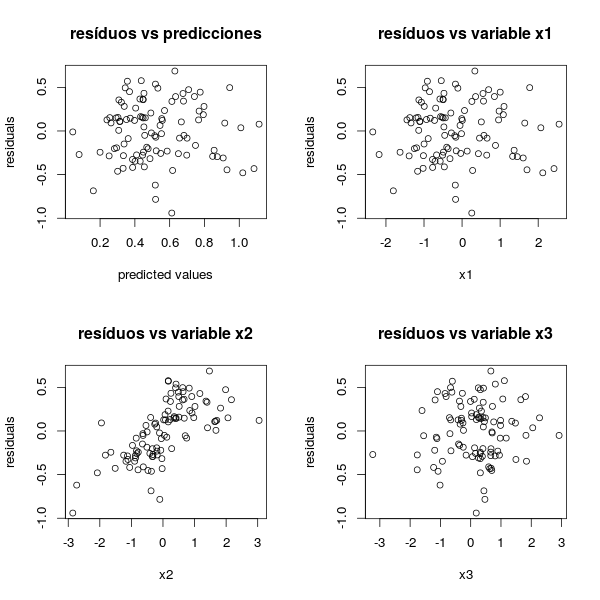
En ninguno de los gráficos de la primera fila (residuos contra predicción y variable explicativa) se aprecian artefactos. Tampoco en el de la esquina inferior derecha (residuos contra una variable que, por construcción, es independiente de y). Sin embargo, al ordenar los residuos según la variable x2, se aprecia una irregularidad. En efecto, el intercepto cambia según x2>0 o no.
Veamos qué hace la función mob de party:
library(party)
plot(mob(y ~ x1 | x2 + x3))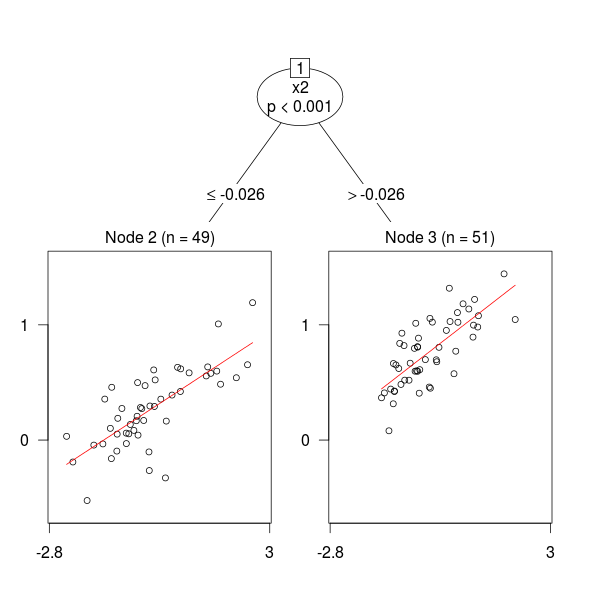
En efecto, mob ha detectado el cambio estructural.
Los autores de party explican todas estas cosas en
- party with the mob: Model-Based Recursive Partitioning in R (accesible) y
- con mucho más detalle y rigor matemático en Generalized M-Fluctuation Tests for Parameter Instability
El segundo artículo está encriptado en jerigonza matemática y es recomendable comenzar a leerlo por el final. Pero no viene a contar otra cosa que lo que he resumido arriba. Es decir, dados unos datos, se selecciona parte de las variables para tratar de predecir otra usando un modelo dentro de una clase relativamente amplia de ellos que incluye los glm. El resto de las variables se reservan para detectar cambios estructurales. Y, a la sazón, regiones del espacio en las cuales el modelo original tiene parámetros distintos. Para cada tipo de modelo los autores identifican una transformación de los datos que genera un vector. Este coincide (¡creo!) con los resíduos en el caso lineal y con alguna generalización de estos en el resto.
Para detectar puntos de corte, estos residuos (los llamaré así) se ordenan de acuerdo con el resto de las variables una a una. De no haber cambios estructurales, los datos deberían seguir una estructura temporal (sí, las técnicas que utilizan se nutren de la teoría de la detección de cambios estructurales en series teporales) determinada, algo así como un ruido blanco. Si no es así (en un determinado nivel de confianza), se da por bueno el cambio estructural, se decide dónde se produce, se le da un tajo al espacio en ese punto de la variable transgresora y se itera sobre los subconjuntos generados.
Dirían los estadísticos más cascarrabias (y Emilio también) que bien podrían incluirse todas las variables en el modelo original. Pero a mí, qué se le va a hacer, me gusta mob.

