La red Asia
La red Asia es esto:
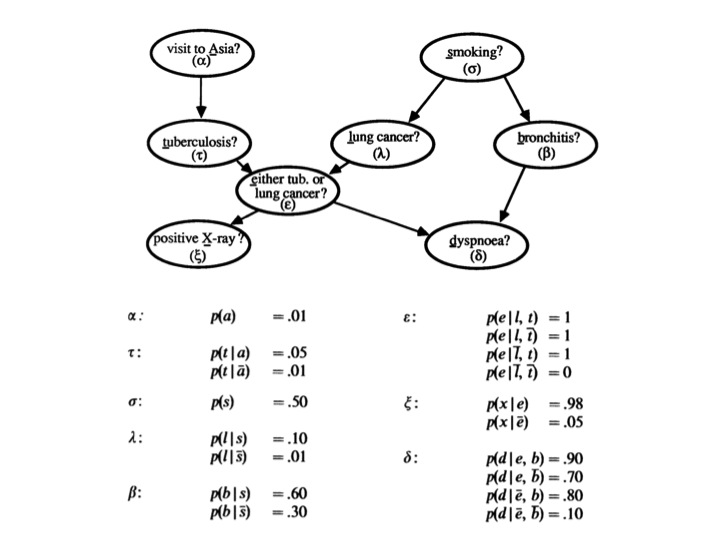
Es decir, una red bayesiana. Una red bayesiana clásica sobre la que los interesados podrán saber más leyendo lo que Lauritzen y Spiegelhalter dejaron escrito sobre ella en 1988.
Pero la idea básica es la siguiente:
- Los nodos superiores (visita a Asia, fumador) son variables observables sobre el comportamiento de unos pacientes.
- Los nodos inferiores (rayos X, disnea) son variables también observables, síntomas de esos pacientes.
- Los nodos centrales, los más importantes, no son observables: son diversas enfermedades que pudieran estar padeciendo los individuos en cuestión.
La pregunta que ayuda a resolver esta red bayesiana es la siguiente: conocidas (¡o no!) las variables observadas, ¿cuál es la probabilidad de que un paciente dado padezca alguna de las enfermedades (tuberculosis, bronquitis o cáncer de pulmón) correspondientes a los nodos centrales?

