Un modelo jerárquico para lo de Casillas
Vuelvo a lo de Casillas inspirándome en el primer ejemplo de este artículo de Gelman et al.
El planteamiento es el siguiente: el número de paradas, $latex n_i$ que realiza el $latex i$-ésimo portero tiene una distribución binomial
$$ n_i \sim B(N_i, p_i)$$
donde $latex N_i$ es el número de disparos entre los palos y $latex p_i$ es la habilidad innata del portero. Estas habilidades innatas siguen una distribución dada, la de habilidades innatas de los porteros de primera división, que podemos suponer que sigue una distribución beta
$$ p_i \sim \text{Beta}(\alpha, \beta)$$
donde $latex \alpha$ y $latex \beta$ tienen una distribución a priori poco informativa (una gamma con una varianza grande).
Puede verse la discusión del artículo de Gelman y compañía para entender el papel de esa distribución de las habilidades de los porteros y el efecto que tendría sobre, por ejemplo, la estimación de la habilidad de un portero que apenas hubiese jugado unos pocos minutos.
El problema de ajustar el modelo en cuestión nos lo resuelve stan:
library(rvest)
library(plyr)
library(reshape2)
library(lattice)
library(rstan)
library(ggplot2)
url <- "http://www.20minutos.es/deportes/estadisticas/liga/player_leaders.asp?category=107"
pagina <- html(url, encoding = "UTF8")
tablas <- html_nodes(pagina, xpath='//*/table')
tabla <- html_table(tablas[2], header = T)[[1]]
tabla <- tabla[, c("Nombre", "Disp.RP", "Par")]
colnames(tabla) <- c("portero", "disparos", "paradas")
datos <- list(N = nrow(tabla),
disparos = tabla$disparos,
paradas = tabla$paradas)
stanmodelcode <- '
data {
int<lower=1> N;
int disparos[N];
int paradas[N];
}
parameters {
vector<lower=0, upper=1>[N] p;
real<lower=0> alfa;
real<lower=0> beta;
}
model {
alfa ~ gamma(10, 1);
beta ~ gamma(10, 1);
for (n in 1:N){
p[n] ~ beta(alfa, beta);
}
for (n in 1:N){
paradas[n] ~ binomial(disparos[n], p[n]);
}
}
'
fit <- stan(model_code = stanmodelcode,
data = datos,
iter=12000, warmup=2000,
chains=4, thin=10)Podemos ver la estimación de la distribución a posteriori de las habilidades de los porteros así:
tmp <- as.data.frame(fit)
tmp$id <- 1:nrow(tmp)
tmp <- melt(tmp, id.vars = "id")
tmp <- tmp[grep("^p", tmp$variable),]
tmp$variable <- as.numeric(gsub("[^0-9]", "",
tmp$variable))
tmp$portero <- tabla$portero[tmp$variable]
tmp$portero <- reorder(tmp$portero,
-tmp$value, median)
ggplot(tmp, aes(x=value)) +
geom_histogram() +
facet_wrap(~portero)que genera
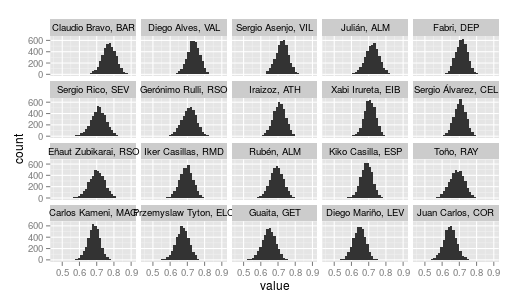
y donde se ve el grado de solape entre las distintas distribuciones. Y otras cosas como, por ejemplo, las distribuciones de los porteros con menos tiros a puerta tienen mayor varianza.
Siguiendo a Gelman et al., una manera de estimar las diferencias entre parejas de porteros sería encontrar el porcentaje de simulaciones en que el estimador de la habilidad de uno de ellos supera al del otro:
foo <- function(p1, p2){
sim1 <- tmp$value[tmp$portero == p1]
sim2 <- tmp$value[tmp$portero == p2]
mean(sim1 <= sim2)
}
diferencias <- outer(tabla$portero,
tabla$portero, Vectorize(foo))
dimnames(diferencias) <- list(tabla$portero, tabla$portero)
significativas <- diferencias
significativas[significativas > 0.1] <- 0.1
levelplot(significativas)que genera

y donde, de nuevo, apenas se encuentran diferencias significativas.
Finalmente, ¿cuál es esa distribución de la habilidad de los porteros de la primera división? print(fit) nos da, entre otras cosas, el valor mediano de $latex \alpha$ y $latex \beta$, 18.14 y 8.27 respectivamente, lo que determina una distribución tal que
foo <- function(x) dbeta(x, 18.14, 8.27)
curve(foo, 0.3, 0.99)Es decir,
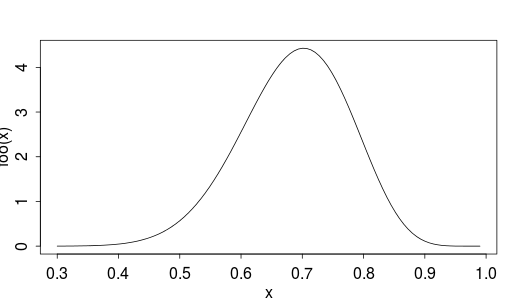
(aunque, más propiamente, una familia de curvas similares a la anterior, porque los parámetros de esa beta tienen su propia distribución).
Lo anterior vienen a contarnos que un portero podría llegar a tener una eficacia del 99%, aunque para ello tendría que demostrarlo muy mucho: atajar prácticamente la totalidad de una cantidad enorme de disparos. No bastaría con atajar uno de uno.
En fin, podría seguir pero termino aquí. Demasiado fútbol (y demasiados nuevos amigos) esta semana ya.

