Colusión de anunciantes en perjuicio de navegantes
O algo así. Aunque alguno puede pensar que no es en su perjuicio sino en su beneficio. A saber.
Solo que con collusion (un plugin para el navegador) uno puede construir gráficos tales como
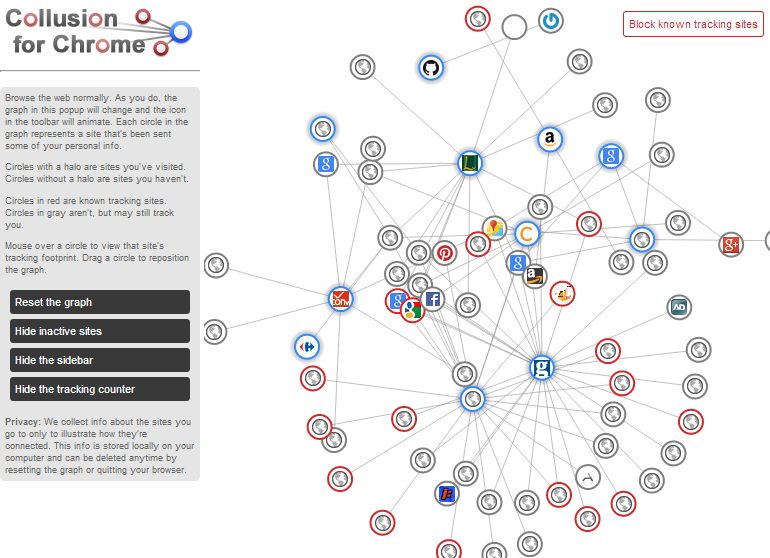
que significa lo que su leyenda dice y que aquí traduzco brevemente. Uno instala en plugin y comienza a navegar por internet. Al hacerlo, collusion detecta esos sitios con los que las páginas que uno visita comparte información a través de galletitas y similares. Algunos de esos sitios pueden ser inofensivos (al parecer, Renfe se ha enterado de que he entrado a marca.es) y otros, los marcados en rojo, pertecen a redes de anunciantes. Más propiamente, a redes de seguimiento de navegantes, que tratan de inferir su perfil para… proporcionarles anuncios a medida, supongo. Estos sitios no solo saben que uno ha aterrizado en una página determinada, sino que pueden seguirlo a través del resto de los sitios que comparten información con él. Por eso en la red que genera collusion aparecen nodos de centralidad elevada (¡hubs!) que corresponden a sitios que colocan sus galletitas por doquier (y previo pago).
La red anterior, en cierto sentido, es la dual de la que aparece aquí. En esta segunda aparecen resaltados los principales sitios de seguimiento de navegantes con los que enlazan algunas páginas populares (en el RU).
Admito que he resumido todo esto fatalmente, mucho peor que aquí, un artículo que recomiendo.
La teoría dice que si uno comienza a navegar por tiendas buscando, p.e., zapatos y luego acude a otro tipo de páginas, en estas uno debería comenzar a encontrar anuncios de zapatos. Todo gracias a esa información que fluye de galletita en galletita. Aunque al tratar de comprobar esta teoría con algún experimento —seguro que mal diseñado— estoy más cerca de darla por mala que por buena. Tal vez porque esas empresas ya saben demasiado de mí.
Sea como fuere, funcione mejor o peor, y dejando de lado los aspectos maquiavélicos de ese mercado, ¿no os parece interesante la posibilidad de realizar análisis de datos de ese volumen y con esa latencia? Sinceramente me pregunto cómo lo harán.

