Detrás de la detección de anomalías en series temporales
Por azares, me ha tocado lidiar con eso de la detección de anomalías. Que es un problema que tiene que ver con dónde colocar las marcas azules en
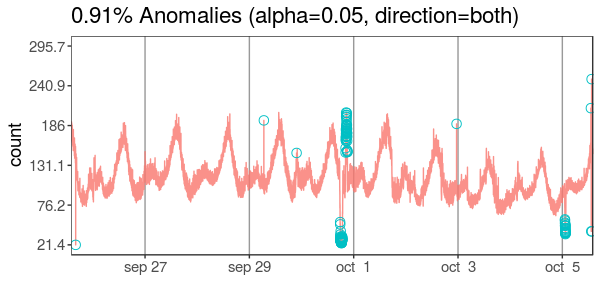
El anterior es el gráfico construido con los datos de ejemplo del paquete AnomalyDetection. De hecho, así:
library(AnomalyDetection)
data(raw_data)
res <- AnomalyDetectionTs(raw_data,
max_anoms=0.02,
direction='both', plot=TRUE)
res$plotAparentemente, AnomalyDetectionTs hace lo que cabría sospechar. Primero, una descomposición de la serie temporal, tal como
myts <- raw_data$count
myts <- ts(myts, start = c(1, 841), frequency = 24 * 60)
plot(stl(myts, "per"))es decir,
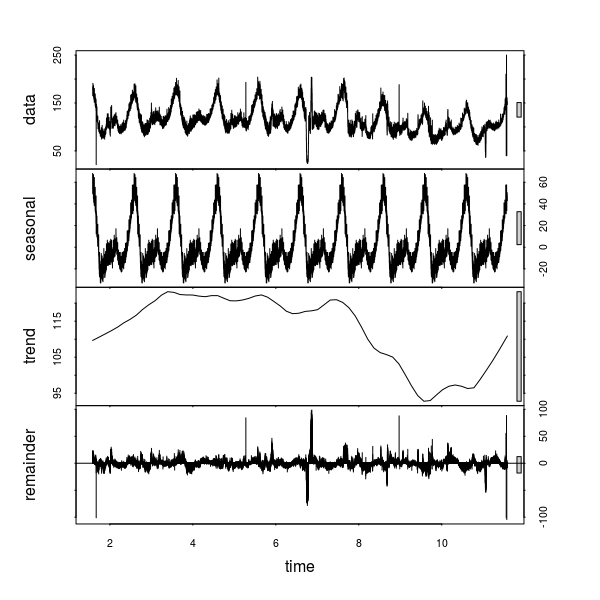
para luego utilizar alguno de esos procedimientos de detección de outliers sobre los residuos, la gráfica de más abajo). Precisamente, este.
Nota: Se me ha olvidado advertir arriba y prominentemente que esta entrada no iba a ser del gusto de quienes por practitioners se tienen. No voy a criticar a nadie por, siempre que no sea en presencia de niños, hacer ostentación del desinterés por conocer el funcionamiento de las cosas. Me parece tan poco propio del ser humano que, a falta de más detalles, me quedaré con la impresión de que lo intentó y no pudo y pasaré a otra cosa.
Me consuela pensar, no obstante, que si alguno ha llegado hasta donde casi termina la entrada —sea por accidente, inercia o, peor aún, curiosidad— habrá prevalecido el provecho sobre el perjuicio que estas pocas líneas con muchas fotos le puedan haber causado.

