GBM (I): Una mentira sugerente
Hace un tiempo resumí los GBMs (Gradient Boosting Machines) en una línea. Hoy comienzo una serie de varias entradas para que nadie tenga excusa de no saber de qué va la cosa. Arranco con una mentira sugerente. Porque lo que voy a contar no es del todo cierto, pero motiva lo que vendrá después.
Consideremos un conjunto de datos medio famoso: el de los precios de los alquileres en Múchich. Comencemos con un modelo sencillo, una regresión lineal que relacione el precio del alquiler con los metros cuadrados, i.e.,
$$ \text{price} \sim a_0 + a_1 \text{size} + \epsilon.$$
Nótese cómo este modelo simple es el que muchos de quienes se dedican al negocio inmobiliario tienen en mente: el precio del alquiler por metro cuadrado se usa a menudo como indicador primero de un mercado. Referirse a ese precio medio es, en esencia, dar por bueno ese modelo.
Pero echemos un vistazo a los residuos. El siguiente gráfico,
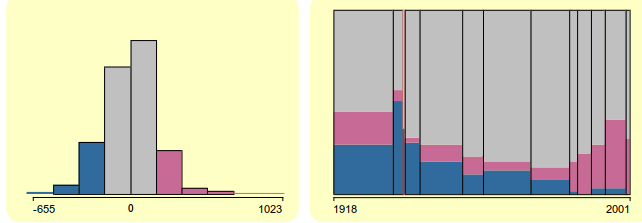
extraído de aquí, muestra tanto el histograma de los residuos como su distribución con respecto a otra variable, el año de construcción del edificio. Como puede apreciarse, esta variable contiene mucha información sobre los precios: el metro cuadrado de los edificios más antiguos tiende a ser inferior al de los nuevos. El modelo simple no captura toda la información del conjunto de datos y podemos hilar más fino usando esta nueva variable.
De querer mejorar nuestro modelo de predicción de precios, se nos abren dos rutas alternativas. La tradicional y más frecuentada es la de introducir la variable antigüedad —preferiblemente centrada o el término independiente será el precio promedio de un apartamento en el Munich del año en que el rey Herodes mataba niños en Palestina— en el modelo, i.e., plantear
$$ \text{price} \sim a_0 + a_1 \text{size} + a_2 \text{anti} + \epsilon.$$
Alternativamente, se puede construir un modelo simple que trate de estimar el valor de los residuos en función del año de construcción, es decir,
$$ p - \hat{p}_i = r \sim a_0 + a_1 \text{anti} + \epsilon.$$
De este modo, nuestra predicción sobre el precio $latex p$ de un apartamento será $latex \hat{p_1} + \hat{p_2}$, es decir, la suma de dos modelos, uno construido sobre los valores de la variable original y otro sobre los residuos.
Nota: aunque está escrito en todas partes, recuerdo que el modelo resultante no es el mismo que el obtenido con una regresión múltiple, nuestra primera alternativa. Una regresión múltiple puede estimarse añadiendo predictores uno a uno, pero no como indico aquí.
Y, retomando el hilo del artículo y proyectándolo más allá, podría pensarse en sumar modelos construidos todos ellos iterativamente sobre los residuos del anterior.
Aun insistiendo que esto no es lo mismo que una regresión múltiple, la idea de sumar modelos simples construidos sobre los residuos anteriores, como veremos, es más profunda y llega más allá de lo que parece a primera vista: no es GBM pero, de alguna manera, lo sugiere.

