Casillas puede ser un portero mediocre, pero quienes analizan sus números lo son aún más
Voy a hablar de fútbol. Voy a comentar esto. Contiene y argumenta alrededor de
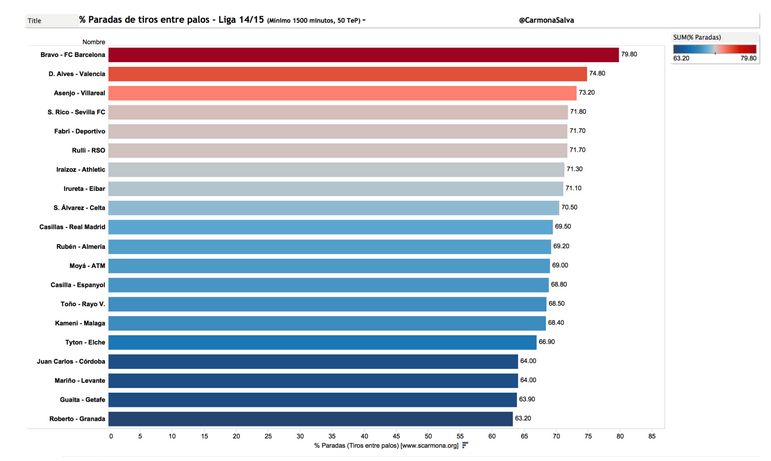
que me puso sobre aviso. Y no, no voy a comentar el amateurismo que manifiesta el hecho de representar dos veces la misma magnitud, el porcentaje de paradas, usando dos significantes distintos (la longitud de las barras y el color). Por más de que siembre la sospecha por lo que sigue.
Me preocupa aún más el hecho de que se ignoren los intervalos de confianza, de que no se vaya más allá de lo que enseñan a los críos de once años y el autor se limite construir un diagrama de barras y un discurso alrededor de él.
Analicemos los datos como se espera que hagan los medios de una sociedad madura. El código
library(rvest)
library(plyr)
library(ggplot2)
url <- "http://www.20minutos.es/deportes/estadisticas/liga/player_leaders.asp?category=107"
pagina <- html(url, encoding = "UTF8")
tablas <- html_nodes(pagina, xpath='//*/table')
tabla <- html_table(tablas[2], header = T)[[1]]
tabla <- tabla[, c("Nombre", "Disp.RP", "Par")]
colnames(tabla) <- c("portero", "disparos", "paradas")
res <- ddply(tabla, .(portero), transform,
lower = prop.test(paradas, disparos)$conf.int[1],
upper = prop.test(paradas, disparos)$conf.int[2],
prop = paradas / disparos)
res$portero <- reorder(res$portero, res$prop, I)
ggplot(res, aes(y = portero, x = prop,
xmin = lower, xmax = upper)) +
geom_point() + geom_errorbarh()descarga el número de tiros a puerta y el de paradas de una página donde constan (los porcentajes son los mismos, luego hay confianza en que la fuente sea común) y genera
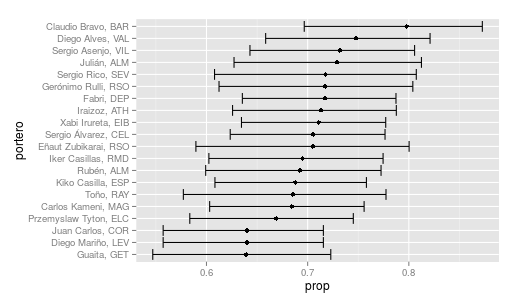
donde se aprecia un manifiesto solapamiento de los intervalos de confianza (al 95%) construidos con prop.test. Las diferencias dejan de parecer ser tan manifiestas. Aún más,
library(lattice)
foo <- function(p1, p2){
paradas1 <- tabla$paradas[tabla$portero == p1]
paradas2 <- tabla$paradas[tabla$portero == p2]
disparos1 <- tabla$disparos[tabla$portero == p1]
disparos2 <- tabla$disparos[tabla$portero == p2]
prop.test(c(paradas1, paradas2), c(disparos1, disparos2))$p.value
}
diferencias <- outer(tabla$portero, tabla$portero, Vectorize(foo))
dimnames(diferencias) <- list(tabla$portero, tabla$portero)
significativas <- diferencias
significativas[significativas > 0.1] <- 0.1
levelplot(significativas)compara dos a dos los porteros usando prop.test y permite construir
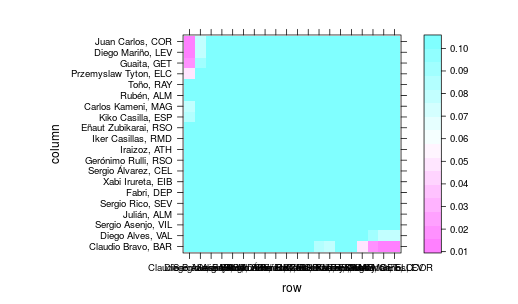
que representa los p-valores de los contrastes (y donde, por exigencias de la escala de colores, a los p-valores mayores de 0.1 se les ha dado el valor de 0.1). Las parejas de porteros que en la matriz tienen un color azul no tienen una eficacia significativamente distinta. Solo las parejas a las que corresponde el color rosa, ¡solo 3!, lo son.
Puede que Casillas no sea el mejor portero del mundo. Pero le da cien vueltas a determinados comentaristas deportivos.
Y cierro con tres comentarios:
- A veces, los números no dicen nada y es mejor callarse. Afortunadamente, estoy en una situación en que me puedo permitir aplicarme el cuento. A otros se les exigen resultados, sean ciertos o no, para ganarse el pan. ¡Pobrecicos!
- La eficiencia de un hospital se mide en términos de estadísticos ajustados por riesgo. No es lo mismo dejarse morir a un infartado que a alguien con una dolencia mucho más leve. Igualmente, no es lo mismo parar un tiro a quemarropa que otro flojón desde fuera del área que da tiempo al portero a peinarse el flequillo. Afortunadamente, nuestra sociedad no está tan enferma como para recoger información detallada sobre la peligrosidad de los tiros a puerta.
- Pese a mis manifestaciones de rigor matemático, he sido muy consciente mientras escribía lo que precede de este artículo en el que se critica lo que he hecho. A ver si saco tiempo estos días para rehacer el estudio como Gelman manda.

