Los coeficientes de la regresión logística con sobremuestreo
Esta entrada viene a cuento de una pregunta en r-help-es con, por referencia, este contexto:
Tengo un dataset con 4505 observaciones en el que la variable dependiente son presencias (n=97 y clasificadas como 1) y ausencias (n=4408 y clasificadas como 0).
Y la cuestión tiene que ver con la conveniencia de utilizar una muestra equilibrada o no de los datos al ajustar una regresión logística y si procede o no utilizar pesos.
Yo quiero mostrar aquí qué sucede con los coeficientes de una regresión logística cuando se submuestrean los ceros. Para eso voy a crear muchos conjuntos de datos con la siguiente estructura:
x1 <- rep(0:1, times = c(n, reps * n))
x2 <- runif(n * (reps + 1))
y <- exp(-1 - 4 * x1)
y <- y/(1+y)
dat$y <- sapply(y, function(x) rbinom(1, 1, x))Hay dos variables independientes, x1 y x2. La segunda es puro ruido. La primera es 0 (casi nunca) o 1 (a menudo). La variable dependiente y es 0 o 1 con una probabilidad que depende de x1: es mucho más probable que sea 1 cuando x1 = 0 (pocas ocasiones) que cuando x1 = 1 (muchas ocasiones). Los coeficientes verdaderos de la regresión logística tal como se ha planteado son c(-1, -4, 0).
Simulemos pues:
library(parallel)
n <- 100
reps <- 20
logistic.bias <- function(n, prop){
x1 <- rep(0:1, times = c(n, reps * n))
x2 <- runif(n * (reps + 1))
dat <- data.frame(x1 = x1, x2 = x2)
res <- replicate(100, {
y <- exp(-1 - 4 * x1)
y <- y/(1+y)
dat$y <- sapply(y, function(x) rbinom(1, 1, x))
keep <- which(dat$y == 1)
n.0 <- pmin(prop * length(keep), sum(dat$y == 0))
keep <- c(keep, sample(which(dat$y == 0), n.0))
dat <- dat[keep,]
coef(glm(y ~ x1 + x2, data = dat, family = binomial()))
})
res <- t(res)
}
props <- c(1:10, 1000)
res <- mclapply(props,
function(x) logistic.bias(1000, x), mc.cores = 8)
out <- lapply(1:length(props),
function(x) data.frame(res[[x]], prop = props[x]))
out <- do.call(rbind, out)
colnames(out) <- c("x0", "x1", "x2", "prop")
boxplot(x2 ~ prop, data = out, main = "x2")
abline(h = 0, col = "red")
boxplot(x1 ~ prop, data = out, main = "x1")
abline(h = -4, col = "red")
boxplot(x0 ~ prop, data = out, main = "x0")
abline(h = -1, col = "red")Hay 100 iteraciones del ajuste de la regresión logísitica sobre 10 proporciones distintas de observaciones y = 1. Cuando prop = 1, los ceros y los unos están equilibrados. Cuando prop = 2, hay el doble de ceros que de unos. Etc. En la última, prop = 1000, se toma la muestra completa.
Veamos el comportamiento de los coeficientes. El de x2, he dejado dicho, es 0 por construcción. Y en efecto:
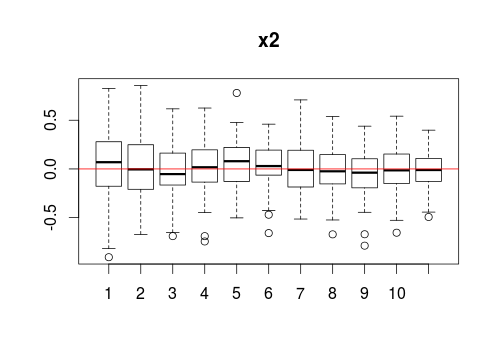
Independientemente de la cantidad de submuestreo, la regresión logística identifica esa variable como ruido.
Igual os sorprende lo que pasa con x1:
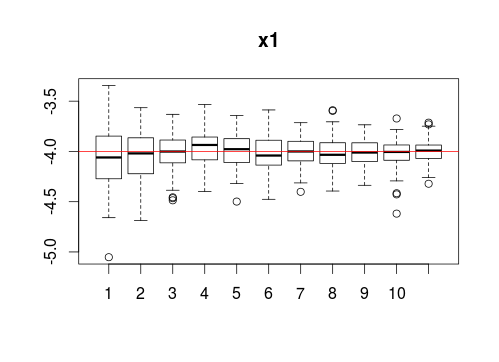
A pesar del submuestreo, el coeficiente no anda lejos de la verdad. Solo que con más observaciones, decrece su varianza.
La diferencia está en x0, el término independiente:
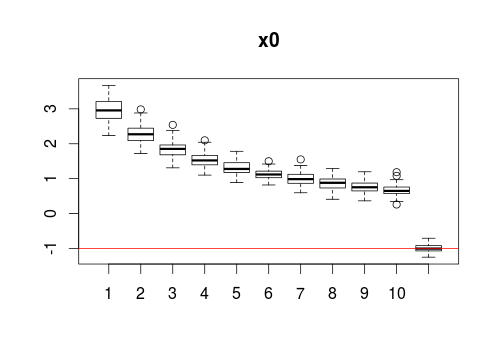
Este varía dependiendo de la agresividad del submuestreo y es el que habría que corregir si de verdad interesa hacerlo. No es difícil realizar la corrección a mano, pero es más sencillo todavía descargarse Logistic Regression in Rare Events Data y consultar la fórmula de la sección 4.1. El mismo artículo (alrededor de la fórmula número 6) también discute el fenómeno de la reducción de la varianza en los estimadores.
Y termino con un consejo-resumen y una advertencia. El primero es que no ha lugar —al menos con la regresión logística— a embarcarse en aventuras de submuestreo.
La segunda es que el término independiente depende de la proporción de unos en la muestra y en la población general. Aun sin submuestreo, puede ser que la muestra esté sesgada con respecto a la población de la que se extrae y, en tal caso, el ajuste que proponen los autores del artículo anterior sigue siendo necesario.

