Censura a la izquierda en las universidades españolas
(Aviso: esta entrada podría competir dignamente en una competición de titulares engañosos. Es posible que si no sepas de qué hablo regularmente te interese más esto).
En España hay pruebas de acceso a la universidad que y en algunos sitios publican las notas de corte para acceder a determinados estudios. Las he bajado escrapeando El País así
library(rvest)
library(plyr)
library(rstan)
library(reshape2)
options(mc.cores = 2)
url <- "http://elpais.com/especiales/universidades/"
pagina <- read_html(url, encoding = "UTF8")
urls_provs <- html_nodes(pagina, "a")
urls_provs <- html_attr(urls_provs, "href")
urls_provs <- paste0("http://elpais.com", urls_provs[grep("centro/provincia", urls_provs)])
foo <- function(url){
tmp <- read_html(url)
urls <- html_nodes(tmp, "a")
urls <- html_attr(urls, "href")
paste0("http://elpais.com", urls[grep("^/especiales/universidades/titulacion/universidad", urls)])
}
urls_univs <- sapply(urls_provs, foo)
urls_univs <- unique(unlist(urls_univs))
foo <- function(url){
tmp <- read_html(url)
lugares <- html_nodes(tmp, xpath = "//*/div[@class = 'lugar']")
data.frame(carrera = html_text(html_nodes(lugares, xpath = "//*/a[@class = 'carrera']")),
sede = html_text(html_nodes(lugares, xpath = "//*/p[@class = 'escuela']/span/a")),
nota = html_text(html_nodes(tmp, xpath = "//*/div[@class='nota']/p/text()")))
}
res <- ldply(urls_univs, foo)
notas <- res
notas$nota <- as.numeric(as.character(res$nota))
# limpieza de datos
notas$nota[notas$nota > 5000] <- notas$nota[notas$nota > 5000] / 1000
notas <- notas[notas$nota > 0,]
notas <- notas[order(notas$nota), ]con el objetivo de estudiar el efecto de la universidad / sede y de la carrera en el punto de corte. Esencialmente, quiero hacer algo así como lmer(nota ~ 1 + (1 | sede) + (1 | carrera), data = notas), pero hay una complicación: como creo que mis lectores sabrán, las notas de acceso tienen un valor mínimo, el del aprobado, 5. Eso significa que, de alguna manera, están censuradas por la izquierda. El modelo resultante es algo así como
$latex \text{nota} \sim N(a + \text{sede} + \text{carrera}, \sigma)$ $latex \text{nota_observada} = \max(5, \text{nota})$
Así que toca renuniciar a lmer y utilizar el sustancialmente más flexible rstan:
n_rows <- nrow(notas)
n_cens <- sum(notas$nota == 5)
n_no_cens <- sum(notas$nota > 5)
ids_carreras <- as.numeric(factor(notas$carrera))
n_carreras <- length(unique(ids_carreras))
ids_sedes <- as.numeric(factor(notas$sede))
n_sedes <- length(unique(ids_sedes))
notas_no_cens <- notas$nota[(n_cens + 1):n_rows]
codigo.stan <- "data {
int<lower=1> n_rows;
int<lower=1> n_cens;
int<lower=1> n_no_cens;
int<lower=1> n_carreras;
int<lower=1> n_sedes;
int ids_carreras[n_rows];
int ids_sedes[n_rows];
real<lower = 5> notas_no_cens[n_no_cens];
}
parameters {
vector[n_carreras] beta_carreras;
vector[n_sedes] beta_sedes;
real<lower=0> sigma;
real<upper = 5> notas_censuradas[n_cens];
real term_indep;
}
model {
beta_carreras ~ normal(0, 4);
beta_sedes ~ normal(0, 4);
term_indep ~ normal(5, 4);
for(i in 1:n_cens){
notas_censuradas[i] ~ normal(term_indep + beta_sedes[ids_sedes[i]] + beta_carreras[ids_carreras[i]], sigma);
}
for(i in 1:n_no_cens){
notas_no_cens[i] ~ normal(term_indep + beta_sedes[ids_sedes[n_cens + i]] + beta_carreras[ids_carreras[n_cens + i]], sigma);
}
}"
fit <- stan(model_code = codigo.stan,
iter=2200, warmup=200,
chains=4, thin=5)En rstan, una de las maneras de introducir la censura en observaciones es considerar las notas no observadas (notas de corte con valor cinco) como parámetros con un valor límite (máximo en este caso) y las observadas como observaciones con un límite inferior (de cinco también en nuestro caso).
Una vez corrida la cosa,
coefs.sedes <- res[,grep("^beta_sedes", colnames(res))]
coefs.sedes$id <- 1:nrow(coefs.sedes)
coefs.sedes <- melt(coefs.sedes, id.vars = "id")
coefs.sedes$sede <- as.numeric(gsub("[^0-9]", "",
as.character(coefs.sedes$variable)))
coefs.sedes$variable <- NULL
coefs.sedes$sede <- levels(notas$sede)[coefs.sedes$sede]
coefs.sedes$sede <- reorder(coefs.sedes$sede, coefs.sedes$value, median)
ggplot(coefs.sedes, aes(x = sede, y = value)) +
geom_boxplot(outlier.shape = NA) + coord_flip()genera algo así como
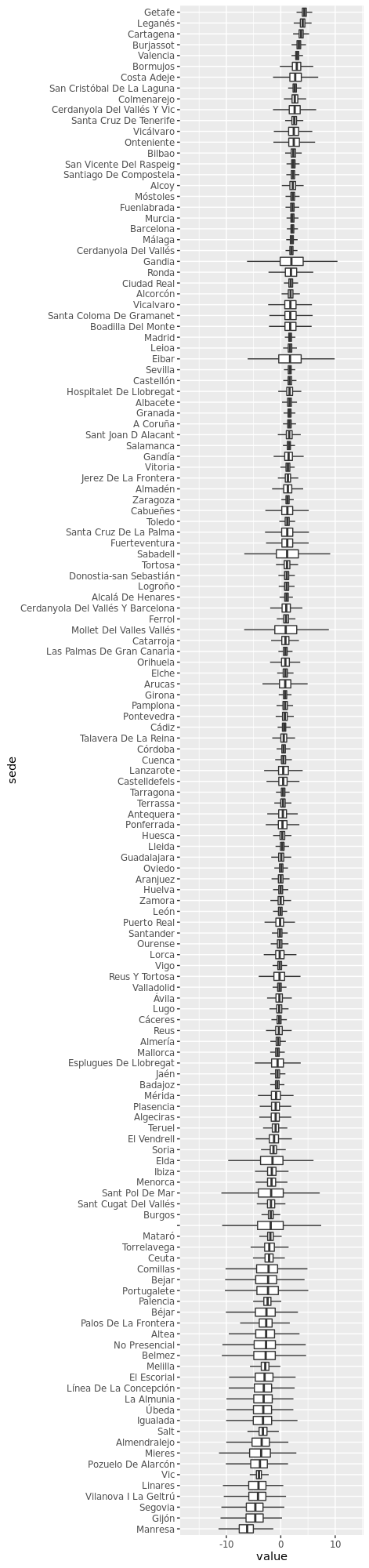
y
coefs.carreras <- res[,grep("^beta_carreras", colnames(res))]
coefs.carreras$id <- 1:nrow(coefs.carreras)
coefs.carreras <- melt(coefs.carreras, id.vars = "id")
coefs.carreras$carrera <- as.numeric(gsub("[^0-9]", "", as.character(coefs.carreras$variable)))
coefs.carreras$variable <- NULL
coefs.carreras$carrera <- levels(notas$carrera)[coefs.carreras$carrera]
coefs.carreras$carrera <- reorder(coefs.carreras$carrera, coefs.carreras$value, median)
ggplot(coefs.carreras, aes(x = carrera, y = value)) +
geom_boxplot(outlier.shape = NA) + coord_flip(), (sí, una coma porque elido el verbo)

Y termino con avisos varios:
- Metí la pata al considerar la sede y no la sede/universidad; así que todo Madrid me ha salido agregado en una única sede.
- Algunas de esas cosas raras de letras parecen estar codeándose en los puestos de cabeza con carreras serias. ¡A saber!
- Supongo que hay más variables implicadas no tenidas en cuenta; para eso, supongo, está la sigma.

