Una interpretación (rápida y sucia) de los coeficientes de la regresión logística
Los coeficientes de la regresión logística tienen una interpretación recta en términos de odds ratio. Que es un concepto sobre el que puede que alguien tenga algún tipo de intuición. Pero yo no.
¿Cómo podemos interpretar, aunque sea de manera rápida y grosera, los coeficientes? En términos de la variación de la probabilidad cuando la variable correspondiente cambia de valor (p.e., en una unidad). El problema es que la probabilidad depende del valor del resto de las variables: la relación no es lineal. No obstante, esa intuición es posible (en algunos casos: véase la nota).
Supongamos que para un sujeto $latex i$, la probabilidad estimada del suceso en cuestión es
$$ p_i = \text{logit}^{-1}(a_0 + a_1 x_{1i} + a_2 x_{2i}).$$
Entonces, si $latex x_{1i}$ se incrementa en una unidad, ¿cómo varía $latex p_i$? Depende. Pero podemos acotar la variación de probabilidad porque
$$ \Delta p_i \approx \frac{\partial \text{logit}^{-1}}{\partial x}(a_0 + a_1 x_{1i} + a_2 x_{2i}) a_1 \Delta x_{1i} < \text{max} \big( \frac{\partial \text{logit}^{-1}}{\partial x} \big) a_1 \Delta x_{1i} = .25 a_1 \Delta x_{1i}$$
(supuesto que tanto $latex a_1 > 0$ como $latex \Delta x_{1i} > 0$). Por lo que la variación de la probabilidad al aumentar el valor de la variable en una unidad es un cuarto del valor del coeficiente en cuestión.
Es un cuarto porque (me da pereza calcular derivadas, ni aun con Wolfram Alfa)
lotgitinvprime <- function(x)
(plogis(x + 0.001) - plogis(x) ) / 0.001
curve(lotgitinvprime, -3, 3,
main = "Derivada de la inversa de la función logística",
ylab = "")produce
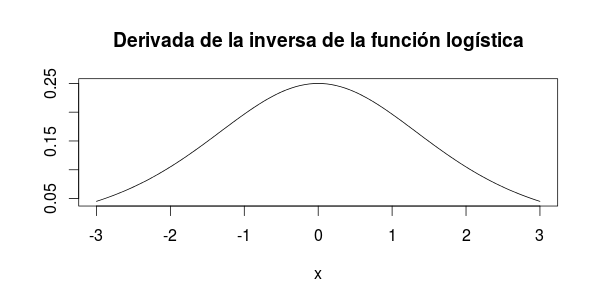
Obviamente, esta variación será menor el score de la observación esté lejos de 0, que es donde está el máximo (de valor .25). Y estará lejos de cero cuando su probabilidad sea extrema: o muy alta o muy baja.
La variación de la probabilidad también depende de la definición de la unidad de medida. Para variables categóricas no existe le problema. Pero las alturas (de las personas, p.e.) se pueden medir en metros, en milímetros o en kilómetros.
Por eso, este truco es menos útil en situaciones en que los eventos tienen baja probabilidad.
En un caso más general, dejo como ejercicio al lector interesado construir una función que, dado un conjunto de datos y una regresión logística construida con ellos, calcule la variación de probabilidad (sujeto a sujeto) obtenida al variar el valor de una variable en una magnitud prefijada.

