Grandes datos, máquinas pequeñas (y regresiones logísticas con variables categóricas)
Preguntaba el otro día Emilio Torres esto en R-help-es. Resumo la pregunta. Se trata de una simulación de unos datos y su ajuste mediante una regresión logística para ver si los coeficientes obtenidos son o no los esperados (teóricamente y por construcción).
El código de Emilio (cuyos resultados no podemos reproducir porque no nos ha contado qué similla usa) es
logisticsimulation <- function(n){
dat <- data.frame(x1=sample(0:1, n,replace=TRUE),
x2=sample(0:1, n,replace=TRUE))
odds <- exp(-1 - 4 * dat$x1 + 7*dat$x2 - 1 *dat$x1* dat$x2 )
pr <- odds/(1+odds)
res <- replicate(100, {
dat$y <- rbinom(n,1,pr)
coef(glm(y ~ x1*x2, data = dat, family = binomial()))
})
t(res)
}
res <- logisticsimulation(100)
apply(res,2,median)
## (Intercept) x1 x2 x1:x2
## -1.0986123 -18.4674562 20.4823593 -0.0512933Efectivamente, los coeficientes están lejos de los esperados, i.e., -1, -4, 7 y 1.
Si hacéis plot(as.data.frame(res)) para ver la distribución entera de los coeficientes estimados en lugar de sus valores centrales, se obtiene algo así como
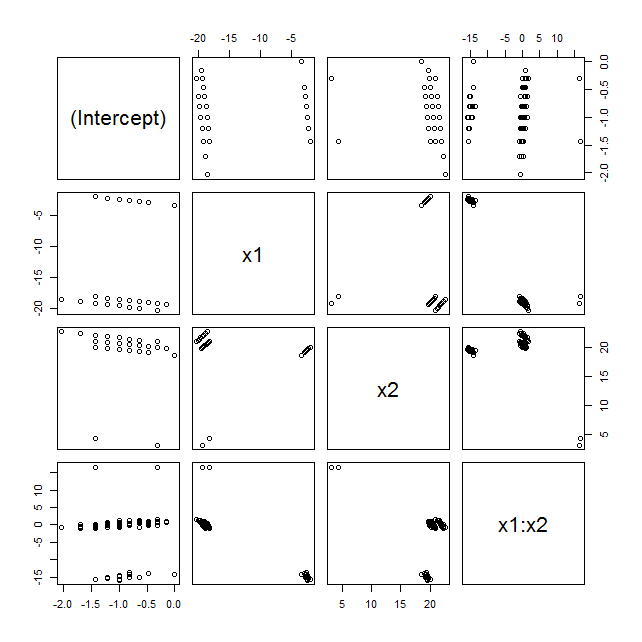
que pone de manifiesto cosas horribles: muchos de los coeficientes estimados tienen distribuciones multimodales en lugar de (aproximadamente) normales alrededor de los valores esperados. Ese tipo de comportamientos suelen estar relacionados con outliers y, en este caso, con un coeficiente de x2 tal alto, valores de y=0 cuando x2=1 prácticamente lo son.
Si uno prueba a repetir el experimento con coeficientes más pequeños, la situación cambia y, digámoslo así, se normaliza.
Alternativamente, uno puede plantearse (como hizo Olivier Núñez en una de las respuestas del hilo arriba enlazado) que en ese caso en que los coeficientes son tan grandes uno aún está lejos de esa asíntota de normalidad que nos garantiza la teoría. Para acercarnos más a ella habría que ensayar con valores de n mayores. Pero, ¿cómo hacerlo sin crear estructuras de datos enormes?
Veámoslo:
logisticsimulation <- function(n){
dat <- data.frame(
x1 = rep(0:1),
times = 2,
x2 = rep(0:1, each = 2))
dat$odds <- exp(-1 - 4 * dat$x1 + 7*dat$x2 - 1 *dat$x1* dat$x2 )
dat$prob <- dat$odds / (1 + dat$odds)
res <- replicate(100, {
dat$exito <- sapply(dat$prob, f
unction(p) rbinom(1, n, p))
dat$fracaso <- n - dat$exito
coef(glm(cbind(exito, fracaso) ~ x1*x2,
data = dat, family = binomial()))
})
t(res)
}
res <- logisticsimulation(1e5)
apply(res,2,median)
plot(as.data.frame(res))En cada iteración, el conjunto de datos dat tiene solo 4 filas que resumen el problema anterior para un conjunto de datos de 4e5 filas. El truco consiste en utilizar la notación glm(cbind(exito, fracaso) ~ x1*x2, data = dat, family = binomial()) para el modelo logístico, que puede ser utilizada para abreviar cálculos con grandes datos en otras situaciones.

